Crawlkit vs LLMWise
Side-by-side comparison to help you choose the right AI tool.
Crawlkit
Crawlkit turns any website into structured data with a single, simple API call.
Last updated: February 28, 2026
LLMWise simplifies AI access with one API for top models, auto-routing responses, and a pay-per-use pricing model.
Last updated: February 28, 2026
Visual Comparison
Crawlkit

LLMWise
Feature Comparison
Crawlkit
Unified API for Diverse Sources
Crawlkit consolidates access to a wide array of data sources under one cohesive API. Whether you're curious about a company's details on LinkedIn, an influencer's metrics on Instagram, app reviews on the Play Store, or real-time web search results, you use the same simple interface. This eliminates the need to learn and maintain multiple scraping tools or adapt to different website structures, allowing you to satisfy your data curiosity across the entire digital landscape with consistent, predictable calls.
Infrastructure Abstraction
The platform expertly handles the most challenging aspects of modern web scraping behind the scenes. This includes managing rotating proxy pools to avoid IP blocks, executing JavaScript in headless browsers to render dynamic content, respecting rate limits, and parsing platform-specific HTML into clean JSON. This feature satisfies a deep curiosity: what if you could access the data without ever worrying about how it's fetched? Crawlkit makes this a reality, letting you explore data collection at scale without operational overhead.
Reliable & Complete Data Delivery
Crawlkit is engineered for reliability, ensuring you receive complete, usable data every time. It patiently waits for full page loads on complex single-page applications (SPAs) and validates all responses before delivery. This means you never have to wonder if a missing data field is due to a parsing error or a failed load. The guarantee of structured, complete outputs allows you to build robust systems and analyses with confidence, turning sporadic data glimpses into a steady stream of insight.
Transparent, Flexible Pricing
Curious about costs? Crawlkit employs a straightforward credit-based system where each API endpoint has a fixed cost, and you only pay for successful requests (with refunds on failures). There are no monthly commitments, no rate limits, and purchased credits never expire. This model encourages experimentation and scales with you, offering volume discounts for larger needs. It answers the fundamental question of value, providing clear, predictable pricing without hidden fees or punitive scaling.
LLMWise
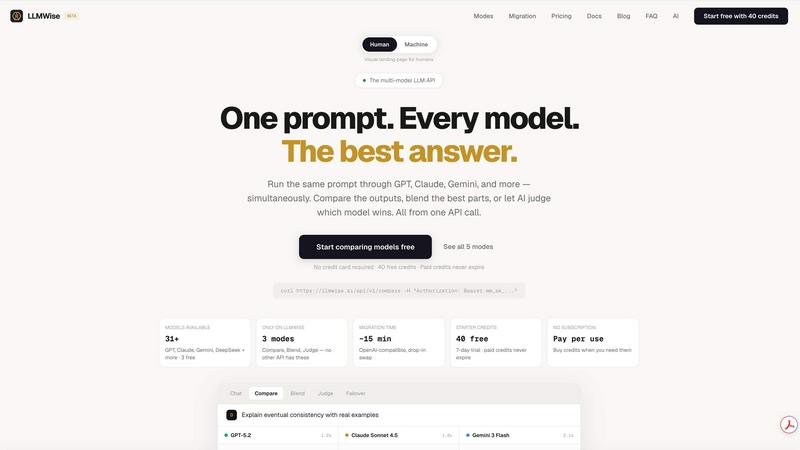
Smart Routing
LLMWise's smart routing feature allows users to send prompts to the platform, which then intelligently selects the optimal model for the task at hand. For example, code-related queries can be directed to GPT, while creative writing tasks might be best suited for Claude. This ensures that every prompt is handled by the most capable model, maximizing efficiency and quality.
Compare & Blend
With the compare and blend functionalities, users can run prompts across multiple models side-by-side. This allows for direct comparison of responses, enabling users to choose the best output. The blend feature takes it a step further by combining the strengths of each model's response into one cohesive answer, enhancing the overall quality of the results.
Always Resilient
LLMWise is built with resilience in mind. The circuit-breaker failover system automatically reroutes requests to backup models if a primary provider experiences downtime. This means that applications using LLMWise remain operational, significantly reducing the risk of disruptions and ensuring constant availability.
Test & Optimize
Developers can take advantage of extensive benchmarking suites, batch tests, and optimization policies to refine their AI interactions. LLMWise offers tools for measuring performance based on speed, cost, or reliability, as well as automated regression checks to ensure consistent quality over time. This empowers users to continually optimize their usage of AI models.
Use Cases
Crawlkit
Competitive Intelligence and Market Research
Imagine automatically tracking your competitors' digital footprints. With Crawlkit, you can systematically monitor their LinkedIn company pages for employee growth and job postings, scrape their app store listings for feature updates and user sentiment, or analyze their public Instagram engagement. This continuous stream of structured data fuels dynamic dashboards and reports, satisfying a deep curiosity about market position and revealing strategic opportunities without manual, repetitive research.
Lead Generation and CRM Enrichment
Sales and marketing teams can transform raw lead lists into rich profiles. By feeding website URLs or company names into Crawlkit's LinkedIn API, you can automatically pull job titles, company information, professional summaries, and other key details to enrich contact records in your CRM. This process turns a simple list of names into a deep, actionable understanding of your potential customers, enabling highly personalized outreach and improving sales conversion rates.
Social Media Monitoring and Growth Tracking
For brands, agencies, or influencers, understanding social performance is key. Crawlkit allows you to programmatically track key Instagram metrics—like follower counts, post engagement rates, and content themes—for your own account or competitors'. Schedule weekly scripts to pull this data and visualize growth trends over time. This use case satisfies the curiosity of what content resonates most and provides data-driven insights to inform your social media strategy.
Product Development and Review Analysis
App developers and product managers can harness direct user feedback at scale. Use Crawlkit to pull all reviews from the Google Play Store or Apple App Store for your app or competing products. Analyze this structured data to uncover common pain points, feature requests, and sentiment trends. This turns the chaotic noise of user reviews into a clear signal, guiding your product roadmap and helping you understand exactly what users love or wish was different.
LLMWise
Software Development
In software development, LLMWise can be utilized to generate code snippets, debug existing code, or provide documentation. By leveraging the smart routing feature, developers can ensure that complex queries are directed to the most capable models, enhancing productivity and reducing errors.
Content Creation
For content creators, LLMWise offers a powerful tool for generating blogs, articles, or social media posts. The compare and blend features allow writers to experiment with different styles and tones, ultimately producing high-quality content that resonates with their audience.
Language Translation
LLMWise is an excellent choice for language translation tasks. By routing translation prompts to the most effective models, users can achieve precise translations that maintain the original meaning. This is especially useful for businesses operating in multiple languages.
AI Research
Researchers can utilize LLMWise to test hypotheses or analyze language models' responses across various AI systems. The testing and optimization features allow for systematic evaluation, providing insights into model performance and capabilities, which can drive innovation in AI research.
Overview
About Crawlkit
Ever wondered how to turn the vast, unstructured data of the web into a clean, reliable stream of information for your projects? Crawlkit is the answer. It's a developer-first web data extraction platform that transforms the complex, often frustrating task of web scraping into a simple API call. Imagine needing data from LinkedIn for sales intelligence, Instagram for social listening, or app stores for market analysis. Instead of wrestling with headless browsers, proxy rotations, and anti-bot countermeasures, Crawlkit abstracts all that infrastructure away. It provides a single, powerful interface to extract structured data from virtually any website or platform, including search engines, social media, and app stores. Built for developers and data teams, its core value proposition is profound simplicity and reliability. You focus entirely on leveraging the data—building applications, enriching CRMs, or training models—while Crawlkit handles the intricate mechanics of collection, parsing, and delivery. With transparent, pay-as-you-go pricing and credits that never expire, it invites you to start small, experiment freely, and scale your data pipelines without lock-in or surprise commitments.
About LLMWise
LLMWise is a revolutionary platform designed to simplify the way developers interact with multiple AI language models. By offering a single API that connects to major providers like OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek, LLMWise eliminates the hassle of managing multiple AI subscriptions. Developers can seamlessly route their prompts to the most suitable model for each task, whether it is coding, creative writing, or translation. The intelligent routing feature ensures that every prompt is matched with the optimal model, enhancing efficiency and accuracy. Targeted towards developers who require the best AI solutions without the added complexity, LLMWise not only streamlines the process but also provides valuable tools for testing and optimizing AI performance. Its unique blend and compare features allow users to synthesize the best outputs from different models, ensuring high-quality results tailored to specific needs. Overall, LLMWise empowers developers to unleash the full potential of AI while minimizing costs and maximizing flexibility.
Frequently Asked Questions
Crawlkit FAQ
What happens if a request fails?
Crawlkit operates on a "succeed or refund" principle. If an API request fails to return the complete, structured data as promised—due to a site being down, a block, or any other issue—the credits used for that request are automatically refunded to your account. This ensures you only pay for successful data delivery, making it risk-free to integrate into automated pipelines.
Do I need to manage proxies or browsers?
No, and that's one of the core benefits. Crawlkit completely abstracts away the infrastructure. The service manages large pools of rotating residential and data center proxies, headless browser instances, and all necessary configurations to navigate anti-bot measures. You simply make an API request and receive clean data, without any operational burden.
How is the data returned?
Data is returned as structured JSON via the API. The structure is clean, consistent, and well-documented for each endpoint (like /linkedin/company or /instagram/profile). For example, a LinkedIn company request might return fields like name, followers, employees, and description, ready to be inserted directly into your database or application logic.
Can I request a new data source or API endpoint?
Absolutely. Crawlkit encourages users to reach out with requests for new platforms or specific data points. Their philosophy, "Need an API we don't have yet? Talk to us, we'll build it," highlights a commitment to expanding their coverage based on user needs. This makes it a collaborative platform that grows with the curiosities and requirements of its developer community.
LLMWise FAQ
How does LLMWise determine the optimal model for each prompt?
LLMWise employs intelligent routing algorithms that analyze the nature of the prompt and match it with the most suitable model based on its strengths and capabilities.
Can I use my existing API keys with LLMWise?
Yes, LLMWise supports the Bring Your Own Key (BYOK) feature, allowing users to integrate their existing API keys for various providers. This flexibility helps to reduce costs and streamline the integration process.
Is there a subscription fee for using LLMWise?
No, LLMWise operates on a pay-per-use model. Users only pay for the credits they consume, and there are no monthly subscription fees or recurring charges, making it a cost-effective solution.
How many models are available through LLMWise?
LLMWise provides access to over 62 models from 20 different providers, including both free and premium options. Users can experiment with 30 models at no cost, allowing for extensive testing and evaluation without financial commitment.
Alternatives
Crawlkit Alternatives
Crawlkit is a modern web data extraction platform, squarely in the analytics and data category. It's designed for developers and data teams who need to bypass the complexities of proxies, browsers, and anti-bot systems to reliably gather web data through a simple API. Users often explore alternatives for a variety of reasons. This curiosity might be driven by specific budget constraints, a need for different feature sets like specialized data sources or integration capabilities, or simply a desire to evaluate the entire landscape before committing to a tool that will power critical data pipelines. When evaluating other options, it's wise to consider several key factors. Look for robust JavaScript rendering for modern websites, high success rates against anti-bot measures, and the scalability to handle your project's volume. The ideal platform should, like Crawlkit, let you focus on using data rather than wrestling with the mechanics of collecting it.
LLMWise Alternatives
LLMWise is a versatile API platform that streamlines access to various large language models (LLMs) such as GPT, Claude, and Gemini, among others. By leveraging intelligent routing, it directs prompts to the most suitable model for each specific task, making it a powerful tool in the realm of AI Assistants. Users often seek alternatives due to factors such as pricing structures, feature sets, and specific platform requirements that may not align with their needs. When considering alternatives, it's essential to evaluate factors such as the variety of models offered, ease of integration, cost-effectiveness, and the flexibility to customize based on unique project demands. Additionally, understanding the support provided and the platform's reliability can greatly influence a user's decision in finding the right solution for their AI needs.