Agenta vs Fallom
Side-by-side comparison to help you choose the right AI tool.
Discover how Agenta's open-source platform helps teams build and manage reliable LLM applications together.
Last updated: March 1, 2026
Fallom offers real-time observability for your AI agents, providing complete visibility and cost tracking.
Last updated: February 28, 2026
Visual Comparison
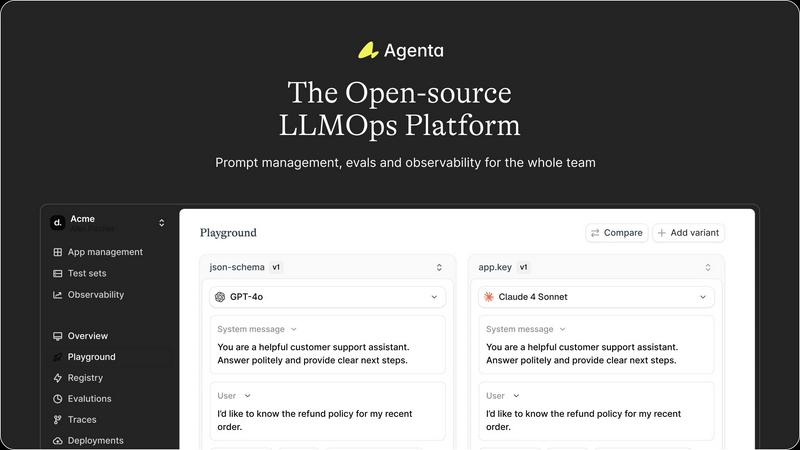
Agenta
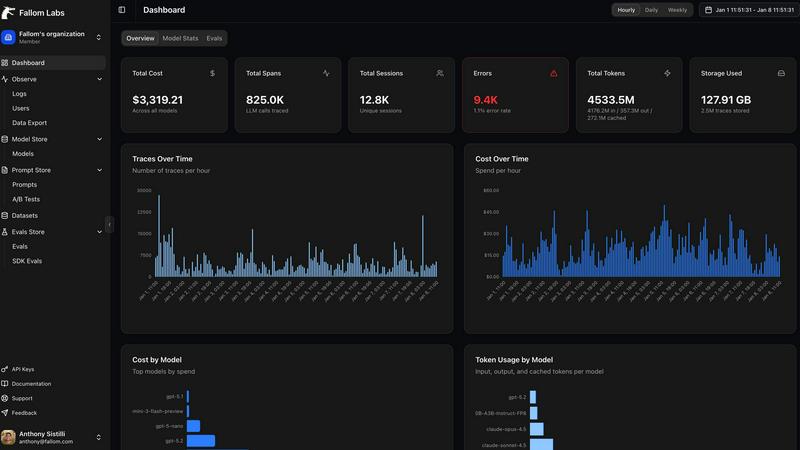
Fallom
Feature Comparison
Agenta
Unified Playground & Experimentation
Dive into a centralized workspace where you can experiment with different prompts, parameters, and foundation models side-by-side. This unified playground allows your entire team to iterate rapidly, compare results in real-time, and maintain a complete version history of every change. Found a problematic output in production? Simply save it to a test set and immediately begin debugging it within the same interactive environment, seamlessly closing the loop between observation and experimentation.
Automated & Holistic Evaluation
Replace intuition with evidence through a systematic evaluation framework. Agenta enables you to create automated test suites using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, it evaluates the full trace of complex AI agents, allowing you to scrutinize each intermediate step in the reasoning process, not just the final output. This deep visibility ensures you can validate that changes genuinely improve performance before they ever reach a user.
Production Observability & Debugging
Gain crystal-clear visibility into your live AI applications. Agenta traces every request, providing a detailed map of your LLM's execution. When errors occur, you can pinpoint the exact failure point—was it the prompt, the model, or a specific function? Furthermore, you can annotate traces with your team or gather direct feedback from users, and with a single click, turn any problematic trace into a permanent test case for future experiments.
Collaborative Workflow for Cross-Functional Teams
Break down the walls between technical and non-technical stakeholders. Agenta provides a safe, intuitive UI for domain experts and product managers to directly edit prompts, run evaluations, and compare experiments without writing code. This fosters true collaboration, ensuring the people with the deepest subject matter expertise can actively shape the AI's behavior, while developers maintain full API and UI parity for programmatic control.
Fallom
End-to-End LLM Tracing
Dive deep into the complete lifecycle of every AI interaction. Fallom automatically captures and visualizes the entire chain of events, from the initial user prompt through each sequential LLM call, tool invocation, and final response. You can explore crucial details like the exact inputs and outputs, token consumption, latency breakdowns, and the associated cost for each step. This granular, waterfall-style visibility is fundamental for understanding agent behavior, identifying bottlenecks, and ensuring the quality of complex, multi-step workflows.
Granular Cost Attribution & Analytics
Ever wondered exactly which model, team, or customer is driving your AI spend? Fallom brings complete financial transparency to your LLM operations. It automatically attributes costs down to the individual call level, allowing you to break down expenses by model provider, specific user, internal team, or even end customer. This enables precise budgeting, accurate chargebacks, and data-driven decisions about model selection, helping you optimize for both performance and cost-efficiency without any financial blind spots.
Enterprise Compliance & Audit Trails
Navigate the evolving landscape of AI regulation with built-in confidence. Fallom is engineered for regulated industries, providing immutable, comprehensive audit trails of all AI interactions. This includes full input/output logging, model version tracking, and user consent recording—features essential for meeting standards like GDPR, SOC 2, and the EU AI Act. Its configurable privacy modes also allow you to redact sensitive data or log only metadata, ensuring compliance without sacrificing essential observability.
Real-Time Dashboard & Live Monitoring
Watch your AI systems operate in real-time with a dynamic, interactive dashboard. See live traces stream in, monitor overall system health, and spot anomalies in usage patterns, latency, or error rates as they happen. This immediate visibility allows teams to proactively identify and troubleshoot issues before they impact users, turning reactive firefighting into proactive system management and ensuring high reliability for your AI-powered applications.
Use Cases
Agenta
Streamlining Enterprise Chatbot Development
Imagine a financial services company building a customer support chatbot. With Agenta, product managers can draft and tweak prompt variations in the UI to ensure compliant and helpful tones, while developers integrate different models from OpenAI or Anthropic. The team can systematically evaluate each version against a test suite of tricky customer queries, monitor its performance in a staging environment, and quickly debug any hallucinated or incorrect advice before a full rollout.
Building and Tuning Complex AI Agents
For teams developing sophisticated multi-step agents that handle tasks like research or data analysis, Agenta is indispensable. Developers can use the platform to trace the agent's entire chain of thought, identifying which tool call or reasoning step failed. They can create evaluations that assess the quality of each intermediate result, not just the final answer, enabling precise tuning of the agent's logic and prompts for maximum reliability.
Managing Rapid Prompt Iteration for Content Generation
A marketing team using LLMs to generate ad copy or blog posts can use Agenta as their central experimentation hub. Writers and marketers can collaborate with engineers to A/B test different creative prompts and models, evaluating outputs for brand voice, SEO effectiveness, and engagement. All successful prompts are versioned and stored, creating a reusable library of high-performing templates that accelerate future content creation.
Academic Research and LLM Benchmarking
Researchers and data scientists can leverage Agenta to conduct rigorous, reproducible experiments. The platform allows them to manage countless prompt and parameter combinations, run large-scale automated evaluations against standardized benchmarks, and meticulously track results. This structured approach turns ad-hoc research into a formalized process, making it easier to validate hypotheses and publish findings.
Fallom
Debugging Complex AI Agent Workflows
When a customer-facing agent fails to book a flight correctly, traditional logging offers only fragments of the story. Fallom allows developers to replay the entire agent session, examining the exact prompts, the data returned from each tool call (like flight search APIs), and the LLM's reasoning at each step. This complete context transforms debugging from a guessing game into a precise, efficient process, dramatically reducing mean time to resolution for intricate AI issues.
Implementing Transparent AI Cost Management
For a SaaS company embedding AI features, uncontrolled costs can quickly derail profitability. Fallom enables finance and engineering leaders to see precisely how much each product feature, customer segment, or internal project is spending on AI. This allows for accurate showback/chargeback models, informed decisions on pricing tiers, and identification of optimization opportunities, such as switching to a more cost-effective model for certain tasks without degrading user experience.
Ensuring Regulatory Compliance for AI Deployments
A healthcare or financial services firm deploying AI assistants must demonstrate strict adherence to data privacy and operational transparency regulations. Fallom provides the verifiable audit trail required, logging every interaction with user context, model versions used, and data processed. Its privacy controls ensure sensitive information can be protected, giving compliance officers the evidence needed to pass audits and build trust with users and regulators.
Optimizing Model Performance & A/B Testing
Choosing the right LLM is critical for application quality and cost. Fallom facilitates robust A/B testing by allowing teams to safely split traffic between different models or prompt versions. You can then compare their performance in real-time across key metrics like accuracy, latency, and cost per call directly within the platform. This data-driven approach takes the guesswork out of model selection and prompt engineering, ensuring you confidently deploy the best-performing configuration.
Overview
About Agenta
What if the journey of building with large language models felt less like a perilous expedition and more like a guided discovery? Agenta is an open-source LLMOps platform crafted to illuminate the path for AI teams navigating the complex terrain of modern LLM development. It transforms the often chaotic and intuitive art of prompt engineering into a structured, collaborative, and evidence-based science. At its heart, Agenta addresses a fundamental paradox: while LLMs are inherently stochastic and unpredictable, the processes teams use to manage, evaluate, and deploy them should be anything but. It serves as the central nervous system for cross-functional teams—including engineers, product managers, and domain experts—who are determined to move beyond scattered prompts in Slack, siloed workflows, and risky "vibe testing." By integrating prompt management, automated evaluation, and production observability into a single, cohesive environment, Agenta becomes the single source of truth for the entire LLM application lifecycle. Its core mission is to empower teams to experiment swiftly, evaluate rigorously, and debug confidently, ultimately turning guesswork into reliable development and shipping robust, high-performing AI applications faster.
About Fallom
What if you could peer inside the intricate conversations of your AI agents, understanding not just their final answers but the entire journey of thought, tool use, and decision-making? Fallom is the key to that exploration. It is a cutting-edge, AI-native observability platform built from the ground up for the unique complexities of Large Language Model (LLM) and autonomous agent workloads. Designed for engineering teams and organizations scaling their AI applications, Fallom provides a comprehensive, real-time window into every AI interaction happening in production. Its core value lies in transforming opaque AI operations into transparent, analyzable, and optimizable processes. With a simple OpenTelemetry-native SDK, you can instantly trace every LLM call, capturing a rich tapestry of data including prompts, outputs, token usage, latency, costs, and the precise sequence of tool calls. This isn't just monitoring; it's about gaining profound, contextual insights. By grouping traces by user, session, or customer, Fallom helps you understand not just what your AI is doing, but who it's for and why it matters. Built with enterprise-scale compliance in mind, it offers the robust audit trails and model governance needed to navigate regulatory landscapes like the EU AI Act. Fallom empowers you to debug with confidence, allocate costs with precision, and ultimately build more reliable, efficient, and transparent AI systems.
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, Agenta is fully open-source. You can dive into the codebase on GitHub, contribute to its development, and self-host the entire platform on your own infrastructure. This ensures there is no vendor lock-in and provides full transparency into how the platform operates, aligning with the needs of many development and research teams.
How does Agenta handle different LLM providers and frameworks?
Agenta is designed to be model-agnostic and framework-flexible. It seamlessly integrates with major providers like OpenAI, Anthropic, and Cohere, as well as popular development frameworks such as LangChain and LlamaIndex. This means you can use the best model for your specific task and switch providers as needed, all within Agenta's consistent management and evaluation workflow.
Can non-technical team members really use Agenta effectively?
Absolutely. A core design principle of Agenta is to democratize the LLM development process. The platform offers an intuitive web UI that allows product managers, domain experts, and other non-coders to safely edit prompts, launch evaluation tests, and visually compare experiment results. This bridges the gap between technical implementation and subject matter expertise.
How does Agenta help with debugging production issues?
When an error occurs in a live application, Agenta's observability traces capture the complete request lifecycle. You can examine the exact prompt sent, the model's raw response, and the output of any intermediate steps. This detailed traceability transforms debugging from a guessing game into a precise investigation, allowing you to quickly identify whether the root cause was a prompt ambiguity, a model limitation, or an integration error.
Fallom FAQ
How does Fallom integrate with my existing application?
Fallom is built on the open standard OpenTelemetry (OTEL), making integration remarkably straightforward. You simply install a single, lightweight SDK into your application code. This SDK automatically instruments your LLM calls—whether you use OpenAI, Anthropic, Google, or other providers—and sends the rich tracing data to the Fallom platform. This means no vendor lock-in and a setup process that can be completed in under five minutes, with no changes to your core application logic.
Can Fallom handle sensitive or private data?
Absolutely. Fallom is designed with enterprise-grade security and privacy controls. It offers a configurable "Privacy Mode" where you can choose to redact specific data fields, log only transaction metadata (like timestamps and token counts), or disable content capture entirely for sensitive environments. This allows you to maintain full observability over system performance and costs while ensuring user data and confidential information are protected according to your policies.
What makes Fallom different from traditional APM tools?
Traditional Application Performance Monitoring (APM) tools are built for conventional software, struggling to interpret the non-deterministic, language-heavy nature of LLM operations. Fallom is AI-native, meaning it understands concepts unique to this domain: it traces semantic prompts and completions, visualizes tool-call sequences, attributes costs per token, and evaluates output quality. It provides the specific context and metrics that AI engineers need, which generic APM tools simply cannot surface.
How does Fallom help with testing and quality assurance?
Fallom includes capabilities for running evaluations on your LLM outputs. You can define custom checks for accuracy, relevance, hallucination rates, or other metrics and run them against sampled or all production traces. This allows you to catch regressions in model performance or prompt effectiveness before they widely impact users. Coupled with its Prompt Store for versioning and A/B testing, it creates a robust framework for continuous improvement of your AI's quality.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to bring order and collaboration to the often chaotic process of building applications with large language models. It acts as a central hub for teams to experiment, evaluate, and manage their LLM prompts and workflows in a structured, evidence-based way. Users often explore alternatives for various reasons. Some may need a solution with different pricing models, whether a fully managed service or a different open-source license. Others might seek specific integrations, deployment options, or feature sets that align more closely with their team's unique workflow or technical stack. When evaluating options, it's wise to consider your team's core needs. Look for tools that foster collaboration across roles, provide robust testing and evaluation capabilities, and offer the flexibility to work with multiple AI models. The goal is to find a platform that turns the unpredictable nature of LLM development into a reliable, repeatable engineering practice.
Fallom Alternatives
Fallom is a specialized observability platform for AI development, focusing on the unique challenges of monitoring Large Language Model and agent-based applications. It provides deep visibility into prompts, costs, and performance, helping teams build reliable and transparent AI systems. Developers and organizations often explore alternatives for various reasons. They might be seeking a different pricing model, a platform that integrates more tightly with their existing infrastructure, or a solution with a broader or narrower feature scope that better matches their specific stage of AI adoption. When evaluating other tools in this space, consider your core needs. Look for robust tracing capabilities, granular cost attribution, and compliance features if required. The ease of instrumentation and the depth of context provided for each AI interaction are also key factors that determine how effectively you can debug, optimize, and govern your LLM workloads.