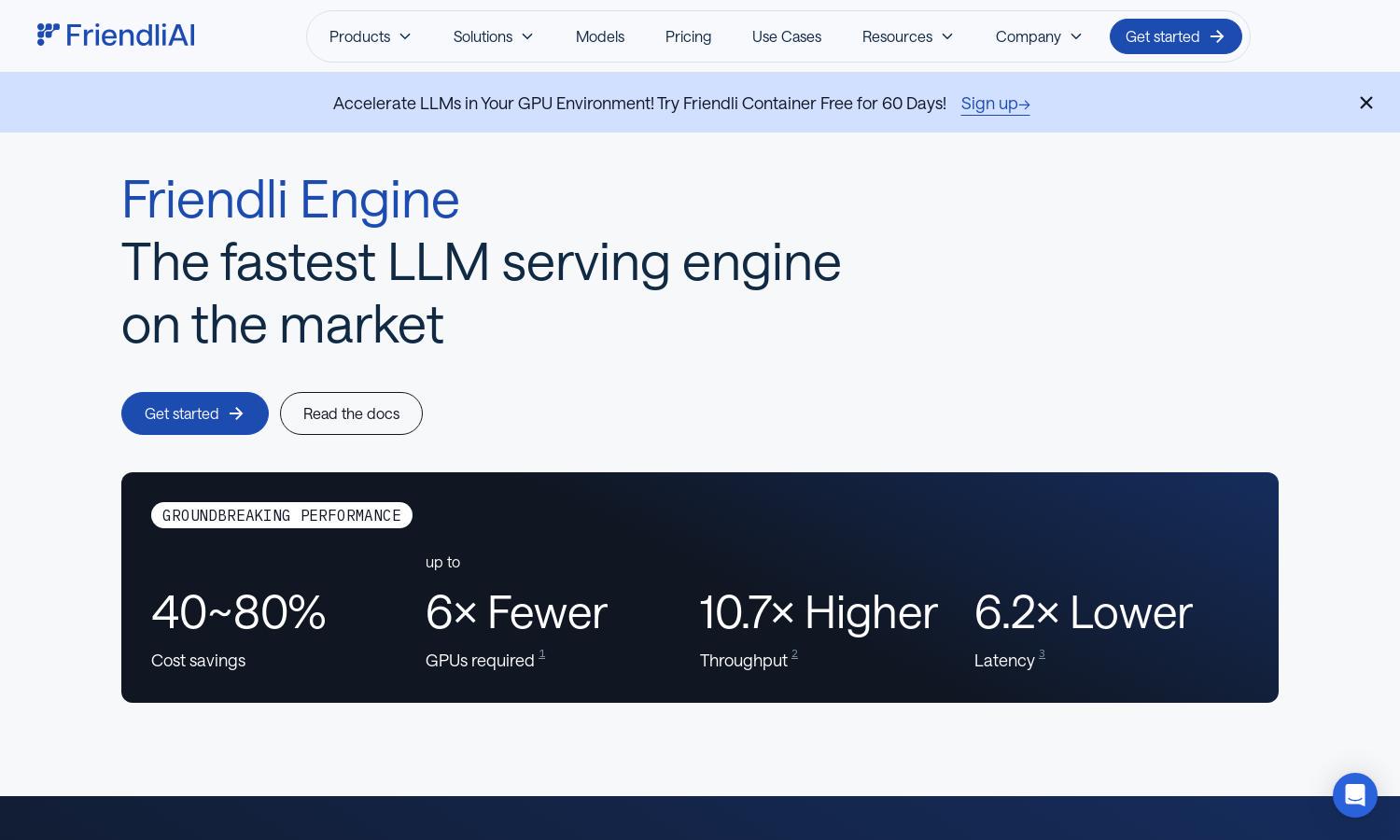
Friendli Engine
About Friendli Engine
Friendli Engine enhances generative AI performance by optimizing LLM inference, targeting developers and businesses needing cost-effective solutions. With groundbreaking features like iteration batching and DNN optimization, users benefit from increased throughput and reduced latency, making it easier to deploy cutting-edge AI solutions efficiently.
Friendli Engine offers multiple pricing tiers tailored for varying usage needs. Each subscription grants access to exclusive features, ensuring maximum LLM inference efficiency. Consider upgrading for enhanced capabilities and better performance metrics, all while enjoying significant cost savings that come with optimized AI solutions.
Friendli Engine's user interface is designed for seamless navigation, featuring an intuitive layout that enhances the user experience. With easily accessible features and streamlined operations, users can efficiently run and manage their generative AI models, ensuring a straightforward and productive interaction with the platform.
How Friendli Engine works
To use Friendli Engine, users start by signing up for an account and selecting a service tier. Next, they can deploy generative AI models via Dedicated or Serverless Endpoints. The platform’s intuitive dashboard simplifies managing models and accessing key features like iteration batching for LLM inference, enabling a smooth user experience.
Key Features for Friendli Engine
Iteration Batching
Iteration batching in Friendli Engine revolutionizes LLM inference by efficiently handling requests. This unique technology dramatically increases throughput while maintaining low latency, enabling users to process more interactions concurrently and enhancing overall performance in generative AI applications.
Multi-LoRA Support
Friendli Engine enables simultaneous multi-LoRA model support, allowing users to run multiple configurations on fewer GPUs. This capability not only enhances customization but also minimizes hardware requirements, making fine-tuning LLMs more accessible and efficient for developers and businesses.
Friendli TCache
Friendli TCache optimizes processing by intelligently caching frequently used computations. This innovative feature significantly reduces workload on GPUs, enhancing response times and making LLM inference more efficient, thus benefiting users by speeding up their AI model interactions without sacrificing accuracy.
You may also like: